本文将介绍通过Java来提取或读取Word文档中文本和图片的方法。这里提取文本和图片包括同时提取文档正文当中以及页眉、页脚中的的文本和图片。
使用工具:Free Spire.Doc for Java (免费版)
Jar文件导入方法(参考):
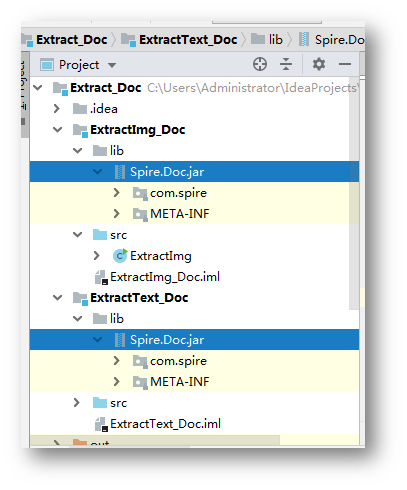
方法1:下载jar文件包。下载后解压文件,并将lib文件夹下的Spire.Doc.jar文件导入到java程序。导入效果参考如下:
方法2:可通过maven导入。参考导入方法。
测试文档如下:

Java代码示例(供参考)
【示例1】提取Word中的文本
import com.spire.doc.*;
import java.io.FileWriter;
import java.io.IOException;public class ExtractText {
public static void main(String[] args) throws IOException{
//加载测试文档
Document doc = new Document();
doc.loadFromFile("test.docx");
//获取文本保存为String
String text = doc.getText();
//将String写入Txt
writeStringToTxt(text,"提取文本.txt");
}
public static void writeStringToTxt(String content, String txtFileName) throws IOException {
FileWriter fWriter= new FileWriter(txtFileName,true);
try {
fWriter.write(content);
}catch(IOException ex){
ex.printStackTrace();
}finally{ try{
fWriter.flush();
fWriter.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
}
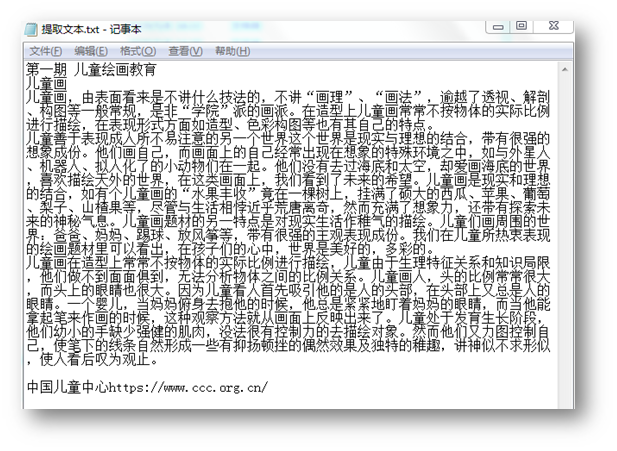
文本提取结果:
【示例2】提取Word中的图片
import com.spire.doc.Document;
import com.spire.doc.documents.DocumentObjectType;
import com.spire.doc.fields.DocPicture;
import com.spire.doc.interfaces.ICompositeObject;
import com.spire.doc.interfaces.IDocumentObject;
import javax.imageio.ImageIO;
import java.awt.image.RenderedImage;
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;public class ExtractImg {
public static void main(String[] args) throws IOException {
//加载Word文档
Document document = new Document();
document.loadFromFile("test.docx");
//创建Queue对象
Queue nodes = new LinkedList();
nodes.add(document);
//创建List对象
List images = new ArrayList();
//遍历文档中的子对象
while (nodes.size() > 0) {
ICompositeObject node = (ICompositeObject) nodes.poll();
for (int i = 0; i < node.getChildObjects().getCount(); i++) {
IDocumentObject child = node.getChildObjects().get(i);
if (child instanceof ICompositeObject) {
nodes.add((ICompositeObject) child);
//获取图片并添加到List
if (child.getDocumentObjectType() == DocumentObjectType.Picture) {
DocPicture picture = (DocPicture) child;
images.add(picture.getImage());
}
}
}
} //将图片保存为PNG格式文件
for (int i = 0; i < images.size(); i++) {
File file = new File(String.format("图片-%d.png", i));
ImageIO.write((RenderedImage) images.get(i), "PNG", file);
}
}
}
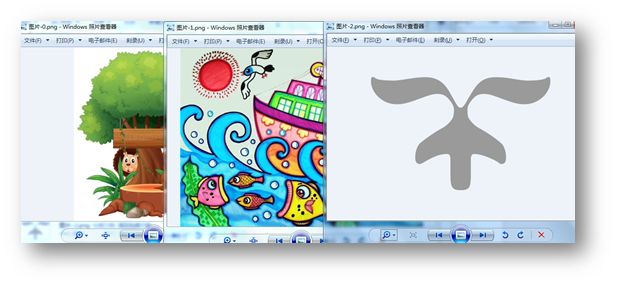
图片提取结果:

发表评论 取消回复